In this Data Engineering course, you will learn how to work with batch and real-time analytics solutions using the technology provided by the Azure data platform. The journey begins with understanding the core computing and storage technologies essential in building analytical solutions. You will discover how to explore data stored in data lakes interactively, using files as your guide. From there, we will cover the various techniques available for data ingestion using prominent tools such as Apache Spark in Azure Synapse Analytics or Azure Databricks, as well as Azure Data Factory or Azure Synapse pipelines. Not only will you learn how to bring data into your analytics systems, but you will also explore different methods to transform this data using the same ingestion tools. As we go further, we emphasize the critical role of security in protecting data whether it’s stored or being transferred. Towards the end, you will learn to create real-time analytics systems, opening doors to crafting solutions that work with data as it comes in, providing insights faster and more accurately. This course is designed to give you hands-on experience and a strong foundation in the fast-paced world of data engineering.
At the end of this course, learners will be able to design and implement various stages and concepts in the data engineering lifecycle, including storage, processing, and security, in Microsoft Azure. Additionally, they will be capable of creating and performing data service operations, such as monitoring and optimization, in Microsoft Azure.
At the end of this course, learners will be able to design and implement various stages and concepts in the data engineering lifecycle, including storage, processing, and security, in Microsoft Azure. Additionally, they will be capable of creating and performing data service operations, such as monitoring and optimization, in Microsoft Azure.
Module 1: Get Started with Data Engineering on Azure
Module 2: Build data analytics solutions using Azure Synapse serverless SQL pools
Module 3: Perform data engineering with Azure Synapse Apache Spark Pools
Module 4: Work with Data Warehouses using Azure Synapse Analytics
Module 5: Transfer and transform data with Azure Synapse Analytics pipelines
Module 6: Work with Hybrid Transactional and Analytical Processing Solutions using Azure Synapse Analytics
Module 7: Implement a Data Streaming Solution with Azure Stream Analytics
Module 8: Govern data across an enterprise
Module 9: Data engineering with Azure Databricks
Required Resources
Laptop, Intel Core i5 or higher, 16GB, 1TB Storage, Graphics Card (Hardware); Microsoft Azure (Software); Adequate Internet Connection (Network)
Pre-Requisites
The primary audience for this course is data professionals, data architects, and business intelligence professionals who want to learn about data engineering and building analytical solutions using data platform technologies that exist on Microsoft Azure. The secondary audience for this course are data analysts and data scientists who work with analytical solutions built on Microsoft Azure.
Assessment
One (1) diagnostic assessment is available, conducted synchronously and is knowledge-based, with the flexibility for learners to choose between remote or on-site participation.
Two (2) formative assessments are offered, one focused on knowledge and the other on performance. Both are available asynchronously, allowing learners to complete them at their own pace, and learners have the option to participate remotely or on-site.
A performance-based summative assessment is to be conducted synchronously, providing learners with the choice of remote or on-site participation.
Credit and Recognition
The learner is eligible to take the Microsoft Certified: Azure Data Engineer Associate.
This course is facilitated by a Microsoft Certified professional. To ensure the quality of this micro-credential, continuous feedback loops with students, instructors, and industry practitioners are maintained to continually improve content, delivery, and assessment methods.
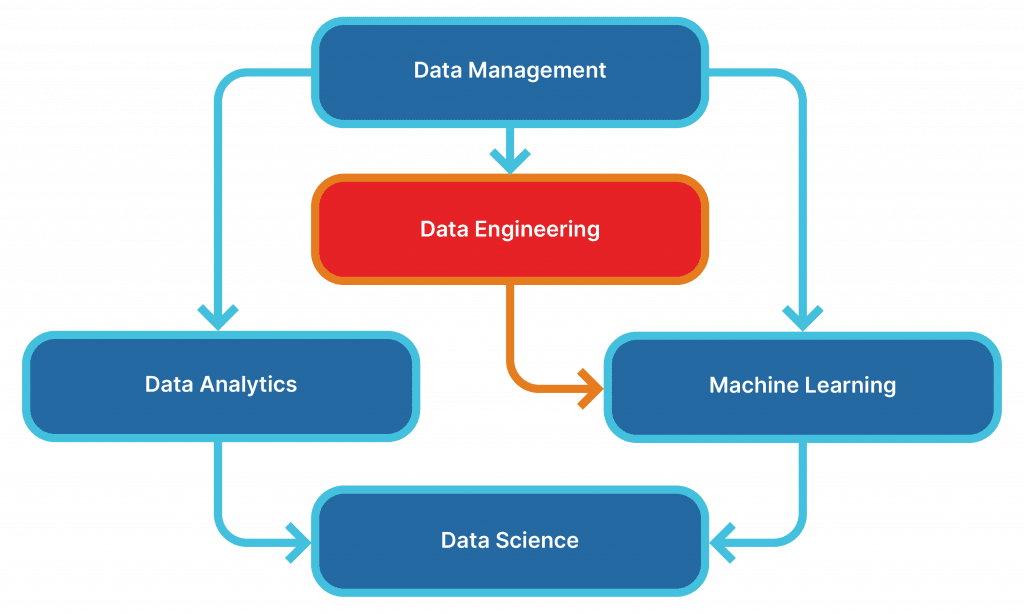
Learning Pathways
Data Management is your prerequisite for entering the world of Data Engineering, where you’ll learn how to architect and manage data pipelines efficiently. Data Engineering is an essential step toward mastering Machine Learning.